A California law firm has filed a class-action lawsuit against OpenAI for "stealing" personal data to train ChatGPT.
Clarkson Law Firm,link download video sex in a complaint filed in the Northern District of California court on Wednesday, alleges ChatGPT and Dall-E "use stolen private information, including personally identifiable information, from hundreds of millions of internet users, including children of all ages, without their informed consent or knowledge." To train its large language model, OpenAI scraped 300 billion words from the internet, including personal information and posts from social media sites like Twitter and Reddit. The law firm claims OpenAI "did so in secret, and without registering as a data broker as it was required to do under applicable law."
SEE ALSO: Lawyers fined $5K for using ChatGPT to file lawsuit filled with fake casesOpenAI has been the subject of controversy for how and what data it collects to train and further develop ChatGPT. Until recently, there was no explicit way for users to opt out of letting OpenAI use their conversations and personal information to feed the model. ChatGPT was initially banned in Italy, using Europe's General Data Protection Regulation (GDPR), for inadequately protecting user data, especially when it comes to minors. This lawsuit includes OpenAI's opaque privacy policies for existing users, but largely focuses on data scraped from the web that was never explicitly intended to be shared with ChatGPT. Through billion-dollar investments from Microsoft and subscriber revenue for ChatGPT Plus, OpenAI has profited from this data without compensating its source.
The 15 counts in the complaint include violation of privacy, negligence for failing to protect personal data, and larceny by illegally obtaining massive amounts of personal data to train its models. Datasets like Common Crawl, Wikipedia, and Reddit, which include personal information, are publicly available as long as companies follow the protocols for purchase and use of this data. But OpenAI allegedly used this data without permission or consent of users in the context of ChatGPT. Even though people's personal information is public on social media sites, blogs, and articles, if data is used outside of the intended platform, it can be considered a violation of privacy.
In Europe, there's a legal distinction between public domain and free-to-use data thanks to the GDPR law, but in the US, that's still up for debate. Nader Henein, a privacy research VP at Gartner who thinks the sentiment of the lawsuit is valid, said, "People should have control as to how their data is used, even when it is available in the public domain." But Henein is unsure if the US legal system would agree.
Ryan Clarkson, managing partner said in the firm's blog post, it's critical to act now with existing laws instead of waiting for Executive and Judicial branches to respond with federal regulation. "We cannot afford to pay the cost of negative outcomes with AI like we’ve done with social media, or like we did with nuclear. As a society, the price we would all pay is far too steep."
Topics Privacy ChatGPT
(Editor: {typename type="name"/})
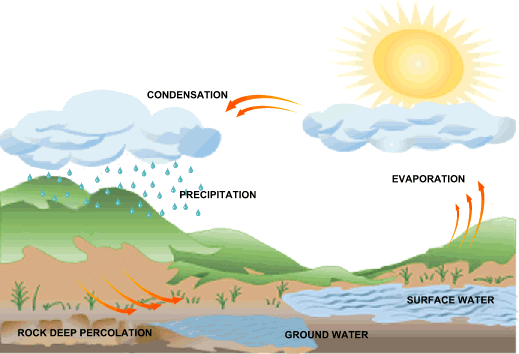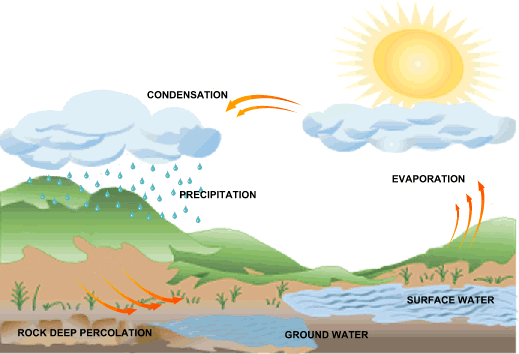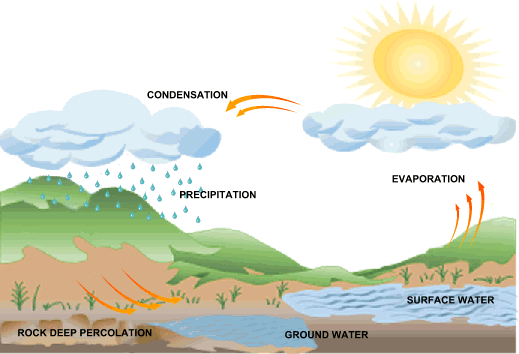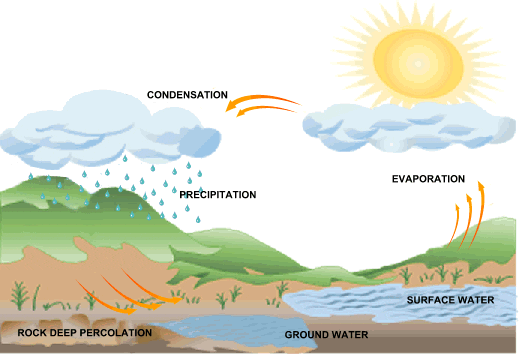 Google's data center raises the stakes in this state's 'water wars'
Google's data center raises the stakes in this state's 'water wars'
 Lorde impersonator fools partygoers into thinking she's the real thing
Lorde impersonator fools partygoers into thinking she's the real thing
 Apple fixes bug that exposed Safari users to money
Apple fixes bug that exposed Safari users to money
 How wrestling legend Diamond Dallas Page found his second act with 'kickass' yoga
How wrestling legend Diamond Dallas Page found his second act with 'kickass' yoga
 Apple's newest ad makes a haunting plea to take climate change seriously
Apple's newest ad makes a haunting plea to take climate change seriously
Elon Musk's DOGE.gov website can apparently be edited by anyone
 Need more proof that Elon Musk's DOGE team, apparently in charge of making the U.S. government more
...[Details]
Need more proof that Elon Musk's DOGE team, apparently in charge of making the U.S. government more
...[Details]
Indian Twitter is standing by Nigerian students facing racial violence
 Indians on social media have come out in support of Nigerian students who faced racial attacks in a
...[Details]
Indians on social media have come out in support of Nigerian students who faced racial attacks in a
...[Details]
Nintendo changed the jump button in 'Splatoon 2' and now everyone's confused
 The Splatoon 2global testfire gave Nintendo Switch owners all over the world a chance to play around
...[Details]
The Splatoon 2global testfire gave Nintendo Switch owners all over the world a chance to play around
...[Details]
Snake on a plane hitches a ride to New Zealand, which has no snakes
 Despite the close distance to Australia, there are no snakes in New Zealand, bar the occasional sea
...[Details]
Despite the close distance to Australia, there are no snakes in New Zealand, bar the occasional sea
...[Details]
 Since its birth in the labs of ARPANET half a century back, Internet has risen to create a truly glo
...[Details]
Since its birth in the labs of ARPANET half a century back, Internet has risen to create a truly glo
...[Details]
Airbnb brings Trips to Australia for a bigger slice of the tourism pie
 Airbnb's ambition to become your travel agent just got an Australian boost.On Tuesday, the company o
...[Details]
Airbnb's ambition to become your travel agent just got an Australian boost.On Tuesday, the company o
...[Details]
Samsung to sell refurbished Galaxy Note 7s in sustainability effort
 Samsung still isn't ready to give up the ghost of the Galaxy Note 7—you know, the phone with t
...[Details]
Samsung still isn't ready to give up the ghost of the Galaxy Note 7—you know, the phone with t
...[Details]
Airbnb brings Trips to Australia for a bigger slice of the tourism pie
Airbnb's ambition to become your travel agent just got an Australian boost.On Tuesday, the company o
...[Details]
SpaceX will try to achieve 2 impressive feats on Monday
 UPDATE: April 30, 2017, 7:21 a.m. EDT SpaceX aborted its launch at the last minute on Sunday due to
...[Details]
UPDATE: April 30, 2017, 7:21 a.m. EDT SpaceX aborted its launch at the last minute on Sunday due to
...[Details]
The tricky art of marketing women's empowerment in the era of Trump
 Just six months ago, millions of Americans thought they were on the brink of electing the country's
...[Details]
Just six months ago, millions of Americans thought they were on the brink of electing the country's
...[Details]
Apple is advertising on Elon Musk's X again

Chance the Rapper wants an intern, unclear if he'll offer college credit

接受PR>=1、BR>=1,流量相当,内容相关类链接。